Why optimizing for Revenue harms Experimentation
why so many Shopify A/B tests are underpowered • how many experiments do companies run • how does a Psychologist use CRO to Ethically Sell Sex Toys

the DANGER of over-monetizing A/B tests 💰⚠️
Stop leading with revenue numbers.
That’s what Product & Experimentation Leader Kevin Anderson says.
Because experimentation isn’t about showing how much money a test made.
It’s about proving
you made the right decision.
When teams present: “This test will generate €2.4M annually.”
It sounds impressive.
But if you overinflate it, it backfires.
People stop believing the numbers.
They question the assumptions.
They question you.
If you monetize a decision?
Be conservative.
“Definitely apply a haircut of -20%.”
Credibility compounds.
Inflated projections don’t.
🔗 Listen the long form podcast on:
i finally figured out why so many Shopify A/B tests are underpowered…
I finally understood this while coaching a CRO agency.
We were inside Intelligems.
And one setting kept popping up:
“Mutually Exclusive” tests.
Not as an exception. As the default.
The team had done everything right:
– calculated MDE
– planned bandwidth
– aligned timelines
And still…
Tests were underpowered.
Sample sizes too small.
Results inconclusive.
Why?
Because of one “protective” setting meant to reduce interaction effects.
Here’s the thing:
The fear of interaction effects is the #1 concern I hear from Shopify owners and junior CROs.
But what if that fear is… overstated?
And what if this one setting is quietly killing your experimentation velocity?
There are moments where it makes sense.
But they’re rarer than most teams think.
I break down:
– when it’s harmful
– when it’s acceptable
– and what most tools don’t tell you
Want to audit & reviews your workflows too?
To 1) deliver work that belongs to the top-10% of agencies and 2) build stronger client relationships and 3) be more confident pitching new work. Check out our CRO Agency & Freelancers Certification »
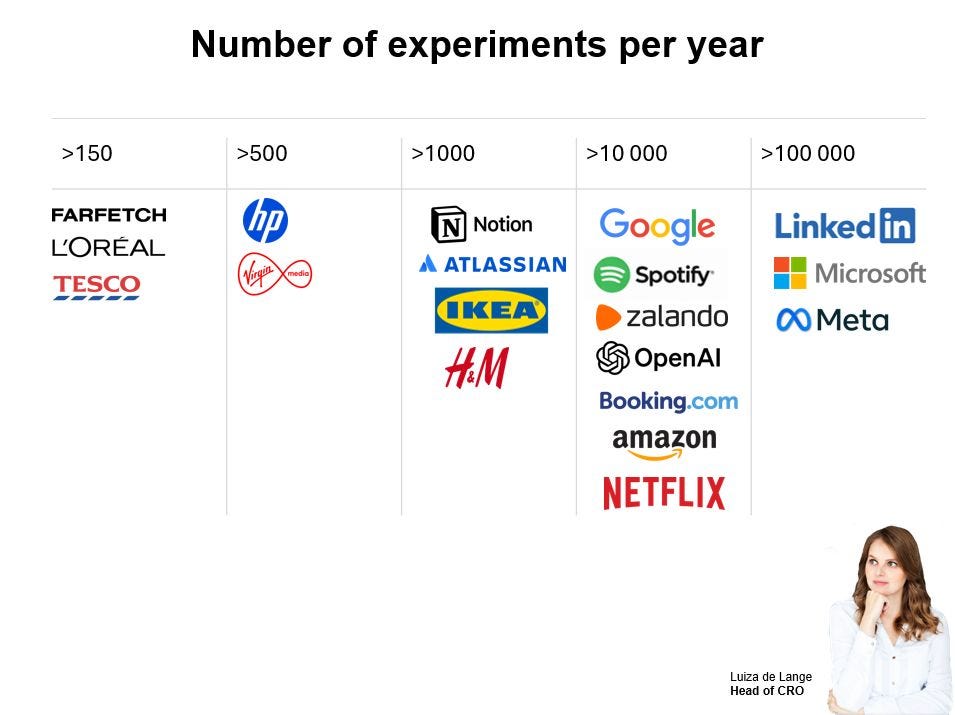
how many experiments do companies run per year?
This is the question every experimentation practitioner secretly wants to know.
Luiza de Lange just put together a fresh look at the numbers — beyond the usual suspects.
She includes newer brands, Swedish companies, and even names like OpenAI and Notion.
Most companies run… let’s just say, fewer tests than you’d expect.
And the reasons why can surprise you: maturity, resources, org changes, infrastructure… velocity shifts for many reasons.
If you want to see the updated benchmarks and get a better sense of what’s actually attainable, check out her post.
🔗 Read Luiza de Lange’s full LinkedIn post
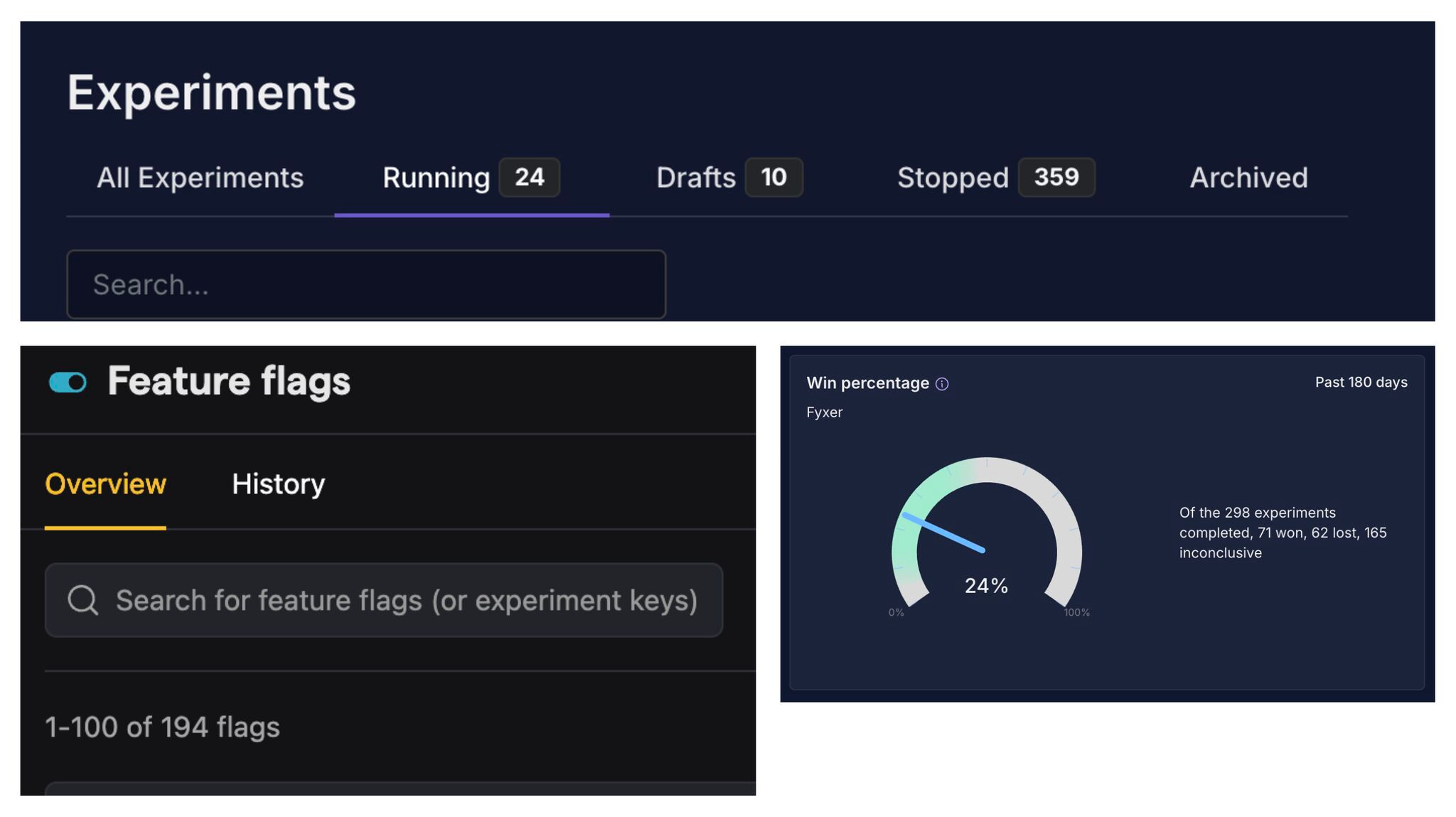
514 experiments in one year 😳
In 2025, Fyxer ran 514 experiments.
That’s the same volume as $1bn+ companies like Monzo and Skyscanner.
The wild part?
Their Growth Engineering team launched 360 of them. This is how Kameron Tanseli (Head of Growth Engineering) made it happen.
Core team size?
4 engineers.
That’s ~90 experiments per engineer per year.
So naturally the question is:
How?
It’s not just “move fast and break things.”
It’s structure.
It’s ownership.
It’s tooling.
It’s hiring founder-type engineers instead of task executors.
It’s letting engineers:
ideate → wireframe → code → launch → iterate.
It’s clear vertical ownership (onboarding, churn, PLG, etc.)
so there’s minimal overlap and fewer bugs.
It’s a simple tech stack.
AI agents cleaning up old tests.
Models one-shotting small experiments.
Automation handling admin.
And most importantly:
Full leadership buy-in.
This is what a modern experimentation engine actually looks like.
If you’re running 10–20 tests per year and wondering why growth feels slow…
this might shift your perspective.
They break down the full setup and stack here 👇
p.s. they are a guest on our podcast next month.
how does a Psychologist use CRO to Ethically Sell Sex Toys and Financial Products?
🎧 podcast: link
📺 youtube: link
are you messing up secondary metrics? 😅
Dr Simon Jackson just shared a really sharp take on secondary experiment metrics.
He points out how even solid teams often get them wrong:
– confusing secondary with exploratory metrics
– not defining them at all
– tracking too many “just in case” metrics
– no pre-defined decision rule
The key takeaway? Secondary metrics should support your hypothesis, not steal the show.
Curious how to structure them properly and avoid these common pitfalls?
get Initial certified
Do you want to stop being an implementer and become a strategic experimentation partner? Next to running the Initial ops, I’ve recently started dedicating my 1:1 time to coaching.
We worked withAndy from Bluelabs and discovered his “system gaps” and helped him become more confident in the work he does.
See what he has to say about the experience.
About the level 1 certification Andy said:
Availability: fast responses on Slack to help with client issues
Great bird eye's view to spot gaps and improve systems
Lots of resources, SOPs and documents she follows up with.
“It’s worth every penny. I’ll come back for more once I’ve applied everything that I learned in her coaching. It’s definitely worth it. Thank you, Lucia!”
Commit now to delivering better CRO work
» retain more clients while building great relationships with them.
» sell high-ticket services and be confident in your work
» move away from being an a/b test factory to a strategic partner